![[파이썬] MediaPipe 객체 인식(objectron)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbYrAUU%2FbtrjPGbJqzK%2FAAAAAAAAAAAAAAAAAAAAALH8bTXmnGRb2Q_Eh2OmvtPv7ltBx8FkpNGqtoxKJJhg%2Fimg.gif%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3D%252FmYVq0b4vgSZsh55qAOvx%252FZBCbA%253D)

원문 : https://google.github.io/mediapipe/solutions/objectron
이 솔루션은 이전에 소개한 솔루션들과 많이 다른 개념을 설명하고 있습니다.
이해하기 어려울 수 있습니다.
개요
MediaPipe의 객체 인식은 일상에서 볼 수 있는 객체를 위한 실시간 3D 객체 감지 솔루션입니다. 2D 이미지에서 객체를 감지하고 객체 인식 데이터 세트에 대해 훈련된 머신러닝(ML) 모델을 통해 객체의 위치 및 포즈를 추정합니다.
 |
 |
 |
 |
| 신발 인식 | 의자 인식 | 카메라 인식 | 컵 인식 |
객체 감지는 광범위하게 연구된 컴퓨터 기술이지만 대부분의 연구에서는 2D 물체 예측에 초점을 맞추고 있습니다. 2D 예측은 곧 3D 예측으로 확장되어 2D 경계 상자를 제공합니다. 이는 현실 물체의 크기, 위치나 방향을 캡처할 수 있어로봇, 자율 주행 차량, 이미지 검색과 증강 현실 등에서 다양한 방법으로 사용되고 있습니다.
 |
| 객체 인식 출력 예제 |
Obtaining Real-World 3D Training Data (실제 3D 학습 데이터 수집)
라이다(LIDAR)같은 3D 캡처 센서에 의존하는 자율 주행 자동차에 대한 연구의 인기로 인해 거리가 있는 장면에는 충분한 양의 3D 데이터가 있지만, 세분화된 일상 물체에 대한 3D 자료는 부족하다. 이 문제를 극복하기 위해 모바일 증간 현실(AR) 세션 데이터를 이용하여 새로운 데이터 파이프라인을 개발했다. ARcore와 ARkit의 등장으로 이제 수억 대의 스마이트폰이 AR 기능과 AR 세션 중 카메라 이동, 아직 약하지만 3D 포인트 클라우드, 예상 조명이나 평면 표면을 포함한 추가 정보를 캡처하는 기능을 가지게 되었습니다.
실측 자료 데이터에 레이블을 지정하기 위해 AR 세션 데이터와 함께 사용할 새로운 주석 도구를 구축했습니다. 이를 통해 주석 작성자는 객체의 3D 경계 상자에 빠르게 레이블을 지정할 수 있습니다. 이 툴은 "분할 화면 보기"를 사용하여 왼쪽에는 3D 경계 상자가 겹쳐진 2D 비디오 프레임을 표시하고, 오른쪽에는 3D 포인트 클라우드와 카메라 위치, 감지된 평면을 보여줍니다. 주석 작성자는 3D 보기에서 3D 경계 상자와 2D 비디오 프레임의 투영을 검토하여 위치를 확인할 수 잇습니다. 움직이지 않는 객체의 경우 단일 프레임의 객체에만 주석을 달고 AR 세션 데이터의 실제 카메라 위치, 이동 정보를 사용하여 모든 프레임에 객체 위치 정보를 전파하기만 하면 되므로 과정이 매우 효율적입니다.

AR Synthetic Data Generation (AR 합성 데이터 생성)
보편적인 접근 방식은 예측의 정확도를 높이기 위해 실제 데이터를 합성 데이터로 보아하는 것입니다. 그러나 그렇게 하려는 시도는 종종 허술하고 비현실적인 데이터를 생성하고 사실적 렌더링의 경우 상당한 노력과 계산이 필요합니다. AR 합성 데이터 생성이라고 하는 새로운 접근 방식은 AR 세션 데이터가 있는 장면에 가상 물체를 배치하여 카메라 위치, 감지된 평면 표면 및 예측 조명을 활용하여 실제로 가능성이 높고 장면과 일치하는 조명을 생성할 수 있도록합니다. 이 접근 방식을 사용하면 장면별 형상을 존중하고 실제 배경에 완벽하게 맞는 객체가 있는 고품질 합성 데이터가 생성됩니다. 실제 데이터와 AR 합성 데이터를 결합하여 정확도를 약 10% 높일 수 있습니다.

ML Pipelines for 3D Object Detection(3D 객체 감지를 위한 머신러닝 파이프라인)
단일 RGB 이미지에서 물체의 3D 경계 상자를 예측하기 위해 두 개의 ML 파이프라인을 구축했습니다. 하나는 2단계 파이프라인이고 다른 하나는 1단계 파이프라인입니다. 2단계 파이프라인은 더 나은 정확도로 1단계 파이프라인보다 3배까지 빠릅니다. 단일 단계 파이프라인은 여러 객체를 감지하는데 좋은 반면, 두 단계 파이프라인은 단일 객체를 감지하는데 좋습니다.
Two-stage Pipeline(두 단계 파이프라인)
우리의 두 단계 파이프라인은 다음 드림의 다이어그램으로 설명된다. 첫 번째 단계에서 객체 감지기를 사용하여 객체의 2D 잘라내기(crop)를 찾습니다. 두 번째 단계에서는 이미지 자르기 작업을 수행하고 3D 경계 상자를 추정합니다. 동시에 객체 감지기가 모든 프레임에서 실행할 필요가 없도록 다음 프레임에 대한 객체의 2D 잘라내기를 계산합니다.
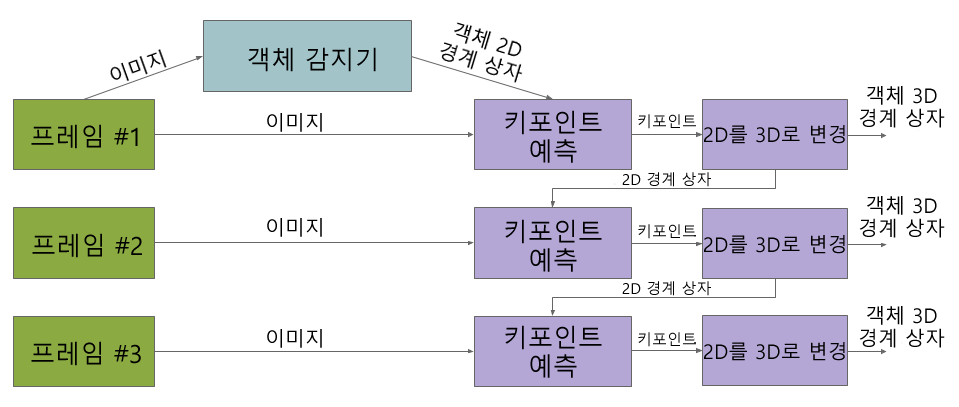
Single-stage Pipeline(단일 단계 파이프라인)

MediaPipe의 단일 단계 파이프라인은 위의 다이어그램으로 설명됩니다. 모델의 백본은 MobileNewv2를 기반으로 하는 인코더-디코더 아키텍처를 가지고 있습니다. 우리는 다중 작업 학습 접근 방법을 사용하여 탐지 및 회귀를 통해 물체의 모양을 예측합니다. 구체화(형상) 작업은 사용 가능한 실측 정보 주석(예: 분할)에 따라 물체의 모양 신호를 예측합니다. 학습 데이터에 형상 주석이 없는 경우 이 옵션은 선택 사항입니다. 탐지 작업을 위해 주석이 달린 경계 상자를 사용하고 상자 중심에 중점을 두고 상자 크기에 비례하는 표준 편차를 사용하여 상자에 가우스(Gaussian)에 맞춥니다. 탐지의 목적은 물체의 중심 위치를 나타내는 피크로 이 분포를 예측하는 것입니다. 회귀 분석 작업은 8개의 상자의 피크의 2D 투영을 추정합니다. 경계 상자의 최종 3D 좌표를 얻기 위해 확립된 포즈 추정 알고리즘(EPnP)을 활용합니다. 개체 치수에 대한 사전 지식 없이 객체의 3D 경계 상자를 복구할 수 있습니다. 3D 경계 상자가 주어지면 포즈와 크기를 쉽게 계산할 수 있스니다. 이 모델은 모바일 장치에서 라이브로 실행 할 수 있을 만큼 가볍습니다. (Adreno 650 모바일 GPU에서 26FPS)
DETECTION AND TRACKING (탐지 및 추적)
모바일 장치가 캡처한 모든 프레임에 모델을 적용하면 각 프레임에서 추정된 3D 경계 상자의 모호성으로 인해 지터가 발생할 수 있습니다. 이를 완화하기 위해 MediaPipe Box Tracking의 2D 객체 감지 및 추적 파이프라인에서 동일한 탐지+추적 전략을 채택합니다. 이렇게 하면 모든 프레임에서 네트워크를 실행할 필요가 줄어들어 더 무겁고 더 정확한 모델을 사용할 수 있으며 파이프라인은 모바일 장치에서 실시간으로 유지됩니다. 또한 프레임 전반에 걸쳐 객체 ID를 유지하고 예측이 일관되도록 유지되어 지터를 줄입니다.
객체 인식 3D 객체 감지 및 추적 파이프라인은 MediaPipe 그래프로 구현되며, 내부적으로 탐지 하위 그래프와 추적 하위 그래프를 사용한다. 감지 하위 그래프는 계산 부하를 줄이기 위해 몇 프레임마다 한 번씩만 ML 추론을 수행하고 출력 텐서를 3D 경계 상자의 중심과 8개의 정점(고정된 점) 등 9개의 핵심점을 포함하는 FrameAnnotation으로 해독한다. 추적 하위 그래프는 MediaPipe Box Tracking의 박스 추적기를 사용하여 3D 경계 상자의 투영을 단단히 감싸고 있는 2D 상자를 추적하고 추적된 2D 키포인트를 EPnP를 사용하여 3D로 들어올립니다. 탐지 하위 그래프에서 새로운 탐지를 사용할 수 있게 되면, 추적 하위 그래프는 또한 중복 영역을 기반으로 탐지 결과와 추적 결과 사이의 통합을 담당합니다.
Objectron Dataset(객체 인식 데이터 세트)
또한 객체 인식 데이터 세트를 공개하여 3D 객체 감지 모델을 교육했습니다. 사용법 및 자습서를 포함한 객체 인식 데이터 세트의 기술 세부 정보는 데이터 세트 웹 사이트에서 확인할 수 있습니다.
Solution APIs
STATIC_IMAGE_MODE (정적_이미지_모드)
false로 설정된 경우 솔루션은 입력 이미지를 비디오 스트림으로 처리합니다. 첫 번째 영상에서 물체를 감지하고 탐지에 성공하면 3D 경계 상자 랜드마크의 위치를 추가로 파악합니다. 후속 영상에서 모든 max_num_objects(객체_최대_갯수) 개체가 감지되고 해당 3D 경계 상자 랜드마크가 기준으로 설정되면 해당 객체를 추적하지 못할 때까지 다른 탐지를 호출하지 않고 이 랜드마크만을 추적합니다. 따라서 대기 시간이 단축되고 비디오 프레임 처리에 이상적입니다. true로 설정하면 객체 탐지가 모든 입력 이미지를 실행하므로 관련이 없는 정적 이미지 일괄 처리에 이상적입니다. 기본값은 false입니다.
MAX_NUM_OBJECTS(객체_최대 갯수)
탐지할 객체의 최대 갯수입니다. 기본값은 5입니다.
MIN_DETECTION_CONFIDENCE (최소_탐지_신뢰도)
탐지가 성공한 것으로 간주되는 객체 탐지 모델의 최소 신뢰값은 ([0.0, 1.0])입니다. 기본값은 0.5입니다.
MIN_TRACKING_CONFIDENCE (최소 추적_신뢰도)
3D 경계 상자 랜드마크 작업이 성공한 것으로 간주되는 랜드마크 추적 모델의 최소 신뢰값은 ([0.0, 1.0])입니다. 그렇지 않으면, 다음 입력 이미지에서 객체 감지가 자동으로 호출됩니다. 이 솔루션을 높은 값으로 설정하면 지연 시간이 길어지는 대신 솔루션의 견고성을 높일 수 있습니다. 객체 감지가 모든 이미지에서 단순히 실행되는 static_image_mode가 True인 경우에는 무시됩니다. 기본값은 0.99입니다.
MODEL_NAME (모델명)
3D 경계 상자 랜드마크를 예측 하는 데에 사용할 모델의 이름입니다. 지금은 {'Shoe', 'Chair', 'Cup', 'Camera'}를 지원합니다. 기본값은 'Shoe'입니다.
모델 명은 순서대로 신발, 의자, 컵, 카메라입니다.
FOCAL_LENGTH (초점_거리)
기본적으로 카메라 초점 거리는 NDC 공간에서 정의됩니다(예: (fx, fy)). 기본값은 (1.0, 1.0)입니다. 대신 픽셀 공간에서 초점 거리(fx_pixel, fy_pixel)를 지정하려면 사용자가 image_size = (image_width, image_height)를 제공하여 API 내에서 변환을 활성화해야 합니다. NDC 및 픽셀 공간에 대한 자세한 내용은 좌표계를 참조하십시오.
PRINCIPAL_POINT (주점)
기본적으로 카메라의 주점은 NDC 공간에서 정의됩니다(예: (px, py)). 기본값은 (0.0, 0.0)입니다. 픽셀 공간의 주요 포인트(예:(px_pixel, py_pixel))를 지정하려면 사용자가 image_size = (image_width, image_height)를 제공하여 API 내에서 변환을 활성화해야 합니다. NDC 및 픽셀 공간에 대한 자세한 내용은 좌표계를 참조하십시오.
IMAGE_SIZE(이미지_크기)
초점 거리 및 주점이 픽셀 공간에 지정된 경우에만 지정하십시오.
입력 이미지의 크기, 즉 (image_width, image_height).
Output(출력)
DETECTED_OBJECTS(탐지된_객체들)
감지된 3D 경계 상자의 리스트입니다. 각각의 3D 경계 상자는 다음과 같이 구성됩니다.
- landmarks_2d(랜드마크_2D) : 객체의 3D 경계 상자의 2D 랜드마크입니다. 이 랜드마크는 좌표는 이미지 너비와 높이에 의해 각각 [0.0, 1.0]으로 정규화됩니다.
- landsmarks_3d(랜드마크_3D) : 객체의 3D 경계 상자의 3D 랜드마크입니다. 이 랜드마크의 좌표는 카메라 좌표 프레임을 표현됩니다.
- rotation(회전) : 객체 좌표 프레임에서 카메라 좌표 프레임까지 회전 행렬합니다.
- translation(변환) : 객체 좌표 프레임에서 카메라 좌표 프레임까지 변환 벡터(동적 배열)합니다.
- scale(비례) : x,z 및 z의 방향에 따른 상대적인 크기입니다.
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_objectron = mp.solutions.objectron
# 이미지 파일의 경우 이것을 사용하세요.:
IMAGE_FILES = []
with mp_objectron.Objectron(static_image_mode=True,
max_num_objects=5,
min_detection_confidence=0.5,
model_name='Shoe') as objectron:
for idx, file in enumerate(IMAGE_FILES):
image = cv2.imread(file)
# BGR 이미지를 RGB로 변환 후 객체 인식 작업을 처리합니다.
results = objectron.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# 박스 랜드마크를 그립니다.
if not results.detected_objects:
print(f'No box landmarks detected on {file}')
continue
print(f'Box landmarks of {file}:')
annotated_image = image.copy()
for detected_object in results.detected_objects:
mp_drawing.draw_landmarks(
annotated_image, detected_object.landmarks_2d, mp_objectron.BOX_CONNECTIONS)
mp_drawing.draw_axis(annotated_image, detected_object.rotation,
detected_object.translation)
cv2.imwrite('/tmp/annotated_image' + str(idx) + '.png', annotated_image)
# 웹캠, 영상 파일의 경우 이것을 사용하세요.:
cap = cv2.VideoCapture(0)
with mp_objectron.Objectron(static_image_mode=False,
max_num_objects=5,
min_detection_confidence=0.5,
min_tracking_confidence=0.99,
model_name='Shoe') as objectron:
while cap.isOpened():
success, image = cap.read()
if not success:
print("카메라를 찾을 수 없습니다.")
# 동영상을 불러올 경우는 'continue' 대신 'break'를 사용합니다.
continue
# 필요에 따라 성능 향상을 위해 이미지 작성을 불가능함으로 기본 설정합니다.
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = objectron.process(image)
# 이미지에 박스 랜드마크를 그립니다.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.detected_objects:
for detected_object in results.detected_objects:
mp_drawing.draw_landmarks(
image, detected_object.landmarks_2d, mp_objectron.BOX_CONNECTIONS)
mp_drawing.draw_axis(image, detected_object.rotation,
detected_object.translation)
# 보기 편하게 이미지를 좌우 반전합니다.
cv2.imshow('MediaPipe Objectron', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()'Python' 카테고리의 다른 글
| [파이썬] MediaPipe 포즈 감지(Pose) (0) | 2021.11.14 |
|---|---|
| [파이썬] OSError: [WinError 123] 파일 이름, 디렉터리 이름 또는 볼륨 레이블 구문이 잘못되었습니다 (0) | 2021.11.12 |
| [파이썬] MediaPipe 손 인식(Hands) (0) | 2021.11.07 |
| [파이썬] 유튜브 영상 mp3 추출 다운로드 (1) | 2021.11.04 |
| [파이썬] MediaPipe 얼굴 그물망(Face Mesh) (0) | 2021.11.03 |
글 내용 중 잘못되거나 이해되지 않는 부분은 댓글을 달아주세요! 감사합니다! 문의: puleugo@gmail.com
![[파이썬] MediaPipe 포즈 감지(Pose)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdCkfR2%2FbtrkoGPmrP8%2FAAAAAAAAAAAAAAAAAAAAANLOhcZYAe_w1bKhbRhVoA1C4drJz3gusyMNpqTdO6UD%2Fimg.gif%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DDbHV0nllCvwUnV1xv4la41f%252Bm2A%253D)
![[파이썬] OSError: [WinError 123] 파일 이름, 디렉터리 이름 또는 볼륨 레이블 구문이 잘못되었습니다](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbxDi7e%2FbtrkgGIZno8%2FAAAAAAAAAAAAAAAAAAAAAEpvo7d9kdEwXfVmjLMPrWsm2G9xsqOQ8vmar5GgvzIU%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3Dn2jn2GE2ppkVZMxPKogthiqPcwM%253D)
![[파이썬] MediaPipe 손 인식(Hands)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F0F4iZ%2FbtrjNZOq1eG%2FAAAAAAAAAAAAAAAAAAAAAE9PJ1EDCa8Zll5PFDn19rx3_V0FdUDHk33sh16afPPW%2Fimg.gif%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DmgbBDdAqrNJe%252B2aEyQUDE4BnkMM%253D)